How to Generate Music using a LSTM Neural Network in Keras
이 문서는 순환신경망(RNN)인
LSTM과 Python 음악 툴킷인music21을 이용해 작곡하는 방법을 설명합니다. 원문 링크2018년 8월을 기준으로, 동작하지 않는 코드는 동작하지 않는 부분을 동작하도록 변형하였기 때문에 코드는 원문과 같지 않을 수 있습니다. 또한 그대로 번역한 것이 아닌 필요한 설명과 합쳐서 다시 쓴 글이기 때문에 원문과 다를 수 있습니다.
모든 이미지들은 원문에서 가져온 이미지입니다. 원문에서 나온 코드의 이해를 돕기 위해 코드에 주석을 붙인 jupyter notebook 파일은 KEKOxTutorial Github에서 확인할 수 있습니다.
주요 키워드
- 케라스
- LSTM
- Neural Networks layer

Introduction
신경망은 우리의 삶을 개선시키는데 이용됩니다. 그것들은 우리가 사고 싶은 물건을 추천하고, 작가의 스타일을 기반으로 텍스트를 생성하며, 심지어 이미지의 미적 스타일을 바꾸는 데 사용되기도 합니다. 최근 몇 년에는, 신경망을 사용하여 텍스트를 생성하는 방법에 대한 여러 튜토리얼이 있었지만 음악을 만드는 방법에 대한 튜토리얼이 부족했습니다. 이 글에서는 Keras 라이브러리를 사용하여 파이썬으로 순환 신경망을 사용하여 음악을 만드는 방법에 대해 설명합니다.
참을성이 부족한 사람들을 위해 이 튜토리얼 끝에 Github 저장소 링크가 있습니다!
Background
구현을 하기 전에 우리가 알아야 할 몇 가지가 있습니다.
Recurrent Neural Networks (RNN)
순환 신경망은 순차적인 정보를 이용하는 인공 신경망의 종류 중 하나입니다. 순환(반복, Recurrent)라고 하는 이유는 시퀀스의 모든 단일 요소에 대해 동일한 기능을 수행하기 때문이고, 각 결과는 이전 연산에 따라 달라집니다. 반면에 기존 신경망들은 이전의 입력에 대해 출력이 독립적입니다.
이 튜토리얼에서 우리는 Long Short-Term Memory(LSTM) 네트워크를 사용할 것 입니다. LSTM은 순환신경망의 하나로 경사 하강을 통해 효율적으로 학습합니다. 게이트 메커니즘을 사용하여 LSTM은 장기 패턴을 인식하고 인코딩할 수 있습니다. LSTM은 음악 및 텍스트 생성의 경우와 같이 네트워크가 오랜 시간 동안 정보를 기억해야 하는 문제를 해결하는 데 매우 유용합니다.
Music21
Music21은 컴퓨터를 활용하는 음악학에 사용되는 Python 툴킷입니다. 우리가 음악 이론의 기초를 가르치고, 음악 예시를 만들고, 음악을 공부할 수 있게 해줍니다. 이 툴킷은 MIDI 파일의 음악 표기법을 습득할 수 있는 간단한 인터페이스를 제공합니다. 또한 노트 및 코드(chord) 객체를 만들어 쉽게 MIDI 파일을 만들 수 있습니다.
이 튜토리얼에서 우리는 Music21을 데이터 세트의 콘텐츠를 추출하고, 음악 표기법으로부터 인공 신경망을 통해 결과값을 얻는데 사용할 것입니다.
이 문서에서는 Anaconda 패키지를 사용하여 가상환경을 만들어서 사용했고, Anaconda를 사용하면 music21을 설치할 필요가 없습니다.
Anaconda 가상환경에서 music21을 설치하려고 한다면 아래와 같이 이미 설치되어 있다는 메세지가 나올 것입니다.
Requirement already satisfied: music21 in /anaconda3/lib/python3.6/site-packages (5.1.0)
music21을 설치할 때는 꼭 최신 버전을 설치하세요!
python2 -> python3 으로 코드 포팅 과정에서 버그 이슈가 있었기 때문에, 해당 이슈가 해결이된 가장 최신의 라이브러리를 다운 받아야 합니다.
Keras
케라스는 텐서플로우와의 상호작용을 단순화하는 고수준 인공 신경망 API입니다. 빠르게 실험을 할 수 있도록 초점을 맞춰서 개발되었습니다.
이 튜토리얼에서는 케라스 라이브러리를 이용해서 LSTM 모델을 만들고 학습시킬 것입니다. 모델이 학습되면 우리는 모델을 음악 표기법으로부터 우리의 음악을 만드는데 사용할 것입니다.
Training (학습)
이 섹션에서는 우리는 모델의 데이터를 수집하는 방법, LSTM 모델과 모델의 아키텍처에서 사용할 수 있도록 데이터를 준비하는 방법에 대해 이야기할 것입니다.
Data
우리의 Github 저장소에서 주로 Final Fantasy 사운드트랙 음악으로 구성된 피아노 음악을 사용했습니다. 우리는 대부분의 곡들이 가지고 있는 독특하고 아름다운 멜로디와 엄청난 양의 곡이 있기 때문에 Final Fantasy 음악을 데이터로 결정했습니다. 하지만 한 개의 악기로 이루어진 모든 MIDI 파일은 데이터로 사용가능합니다.
인공 신경망을 구현하는 첫 번째 스텝은 사용할 데이터를 검사해보는 것입니다.
아래에서 Music21을 사용해 Midi 파일로부터 얻은 결과를 볼 수 있습니다.
...
<music21.note.Note F>
<music21.chord.Chord A2 E3>
<music21.chord.Chord A2 E3>
<music21.note.Note E>
<music21.chord.Chord B-2 F3>
<music21.note.Note F>
<music21.note.Note G>
<music21.note.Note D>
<music21.chord.Chord B-2 F3>
<music21.note.Note F>
<music21.chord.Chord B-2 F3>
<music21.note.Note E>
<music21.chord.Chord B-2 F3>
<music21.note.Note D>
<music21.chord.Chord B-2 F3>
<music21.note.Note E>
<music21.chord.Chord A2 E3>
...
데이터는 두가지 타입으로 구분됩니다: 노트와 코드(chord)입니다. 노트에는 노트의 계이름, 옥타브 및 오프셋에 대한 정보가 포함되어 있습니다.
-
계이름은 소리의 주파수 또는 소리의 높낮이를 의미하고, “A, B, C, D, E, F, G”와 같이 표현됩니다.
-
옥타브는 피아노에서 어떤 계이름 셋을 사용하는지를 나타냅니다. 예를 들어, 피아노에 도레미파솔라시도레미파솔라시도 가 존재한다고 할 때 ‘첫 번째 도’와 ‘마지막 도’는 둘 다 ‘도’ 이지만 높이가 다릅니다. 이 두 개의 도를 서로 다른 옥타브의 도라고 표현합니다.
-
오프셋은 노트가 해당 피스에서 위치한 위치를 나타냅니다.
그리고 코드(chord)는 동시에 연주되는 노트 세트를 위한 컨테이너입니다.
이제 우리는 정확하게 음악을 만들어내기 위해서는 우리의 신경망이 다음에 어떤 음이 될지 예측할 수 있어야 한다는 것을 알 수 있습니다. 그 말은 트레인 세트에 관여한 모든 노트와 코드(chord) 개체를 예측값 배열이 갖고 있다는 것입니다. Github 페이지에 있는 트레인 세트에는 총 개수가 다른 노트와 코드(chord)가 352개 있습니다. 네트워크가 처리할 수 있는 많은 가짓수의 예측값이 있는 것처럼 보이지만, LSTM 네트워크는 쉽게 처리할 수 있습니다.
다음으로 우리가 노트를 어디에 두어야 할지 생각해봐야 합니다. 대부분의 사람들이 음악을 들었을 때처럼, 노트들 사이에는 다양한 간격이 있습니다. 우리는 많은 노트를 빠르게 연주하다가 노트 없이 잠깐 멈추도록 연주할 수도 있습니다.
아래에는 Music21을 사용하여 읽은 Midi 파일에서 발췌한 것이 있습니다. 다만 이번에는 뒤에 있는 개체의 오프셋을 추가했습니다. 이렇게 하면 각 노트와 코드(chord) 사이의 간격을 볼 수 있습니다.
...
<music21.note.Note B> 72.0
<music21.chord.Chord E3 A3> 72.0
<music21.note.Note A> 72.5
<music21.chord.Chord E3 A3> 72.5
<music21.note.Note E> 73.0
<music21.chord.Chord E3 A3> 73.0
<music21.chord.Chord E3 A3> 73.5
<music21.note.Note E-> 74.0
<music21.chord.Chord F3 A3> 74.0
<music21.chord.Chord F3 A3> 74.5
<music21.chord.Chord F3 A3> 75.0
<music21.chord.Chord F3 A3> 75.5
<music21.chord.Chord E3 A3> 76.0
<music21.chord.Chord E3 A3> 76.5
<music21.chord.Chord E3 A3> 77.0
<music21.chord.Chord E3 A3> 77.5
<music21.chord.Chord F3 A3> 78.0
<music21.chord.Chord F3 A3> 78.5
<music21.chord.Chord F3 A3> 79.0
...
위의 midi 파일에서 읽은 노트, 코드(chord)들을 보면 노트 사이에 가장 일반적인 간격은 0.5입니다. 그러므로 우리는 출력이 가능한 다양한 오프셋을 무시함으로써 데이터와 모델을 단순화할 수 있습니다. 이렇게 단순화 시킨다고 해서 네트워크가 생성하는 음악의 멜로디에 너무 큰 영향을 미치지 않을 것입니다. 따라서 본 튜토리얼에서는 오프셋을 무시하고 가능한 출력 개수를 352로 유지합니다.
Preparing Data (데이터 준비하기)
데이터를 보고 LSTM 네트워크의 입력 및 출력이 노트와 코드(chord)라는 것을 확인했으므로 네트워크를 위한 데이터를 준비할 때입니다.
먼저 아래 code의 일부분에서 볼 수 있는 것처럼 데이터를 배열에 로드합니다.
from music21 import converter, instrument, note, chord
import glob # 원문에는 없지만 아래에서 사용하기 때문에 glob을 import 해줘야합니다.
notes = []
for file in glob.glob("midi_songs/*.mid"):
midi = converter.parse(file)
notes_to_parse = None
try: # 학습 데이터 중 TypeError 를 일으키는 파일이 있어서 해놓은 예외처리
parts = instrument.partitionByInstrument(midi)
except TypeError:
print('## 1 {} file occur error.'.format(file))
if parts: # file has instrument parts
print('## 2 {} file has instrument parts'.format(file))
notes_to_parse = parts.parts[0].recurse()
else: # file has notes in a flat structure
print('## 3 {} file has notes in a flat structure'.format(file))
notes_to_parse = midi.flat.notes
for element in notes_to_parse:
if isinstance(element, note.Note):
notes.append(str(element.pitch))
elif isinstance(element, chord.Chord):
notes.append('.'.join(str(n) for n in element.normalOrder))
위의 code를 어느 정도 이해하기 위해서는 code 안에서 사용하는 music21 라이브러리의 함수들을 알아야합니다.
그래서 music21 document를 보고 함수들을 최대한 설명했으나 음악과 음악 관련 소프트웨어에 대해서 잘 알지 못하기 때문에 어려울 수 있으니, 직접 한 번 각 함수의 설명을 읽어보는 것을 추천합니다.
- music21.converter : 다양한 음악 파일 포맷으로부터 음악을 로드하는 툴을 가지고 있습니다.
- music21.converter.parse() : 파일의 아이템을 파싱하고 스트림에 넣어줍니다.
- instrument.partitionByInstrument() : 단일 스트림, 스코어, 멀티 파트 구조인 경우에 각각의 악기별로 파티션을 나누고 다른 파트들을 하나로 합쳐줍니다.
- Stream.recurse : 스트림안에 존재하는 Music21 객체가 가지고 있는 값들의 리스트를 반복(iterate)할 수 있는 iterator 를 리턴해줍니다.
먼저 convert.parse(file) 기능을 사용하여 각 파일을 Music21 스트림 개체로 로드합니다. 그 스트림 개체를 사용하면 파일에 있는 모든 노트와 코드(chord) 목록이 나옵니다. 노트의 가장 중요한 부분은 계이름의 문자열 표기법을 사용하여 다시 만들 수 있으므로 모든 노트 객체의 계이름을 문자열 표기법으로 추가합니다. 그리고 우리는 각 음을 점으로 나누어서 현 안에 있는 모든 음들의 id를 하나의 문자열로 인코딩함으로써 모든 화음을 추가합니다. 이러한 인코딩을 통해 네트워크에 의해 생성된 출력을 올바른 노트와 코드(chord)로 쉽게 디코딩할 수 있습니다.
이제 모든 노트와 코드(chord)를 순차적 목록에 넣었으므로 네트워크의 입력으로 사용될 시퀀스를 만들 수 있습니다.
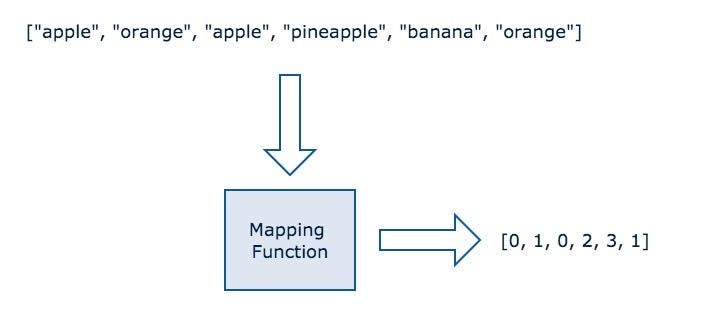
먼저, Figure 1에서 설명한 것처럼 문자열 데이터를 숫자 형식으로 나타내는 일을 진행할 것입니다. 이렇게 하는 이유는 문자열 기반 데이터보다 숫자 기반 데이터를 신경망이 더 잘 학습하기 때문입니다.
다음으로, 우리는 네트워크와 각각의 출력에 대한 입력 순서를 만들어야 합니다. 각 입력 시퀀스의 출력은 노트 리스트의 입력 시퀀스에서 노트의 시퀀스 뒤에 오는 첫 번째 노트 또는 코드입니다.
sequence_length = 100
# 모든 계이름의 이름을 pitchnames 변수에 저장.
# set 으로 중복을 피하고, sorted 함수로 정렬함.
pitchnames = sorted(set(item for item in notes))
# 각 계이름을 숫자로 바꾸는 dictionary(사전)을 만든다.
note_to_int = dict((note, number) for number, note in enumerate(pitchnames))
network_input = []
network_output = []
# 입력 시퀀스를 만든다.
for i in range(0, len(notes) - sequence_length, 1):
sequence_in = notes[i:i + sequence_length]
sequence_out = notes[i + sequence_length]
network_input.append([note_to_int[char] for char in sequence_in])
network_output.append(note_to_int[sequence_out])
n_patterns = len(network_input)
# 데이터 입력 형태를 LSTM 레이어에 알맞게 변경함.
network_input = numpy.reshape(network_input, (n_patterns, sequence_length, 1))
# 입력값을 normalizing(정규화)
network_input = network_input / float(n_vocab)
network_output = np_utils.to_categorical(network_output)
code 예에서 각 시퀀스의 길이는 100노트/코드(chord) 입니다. 즉, 네트워크에서 다음 노트를 예측하기 위해서 도움이 되는 이전 100개의 노트를 사용한다는 뜻입니다. 다른 시퀀스 길이를 사용했을 때 네트워크가 생성하는 음악에 미칠 수 있는 영향을 확인하기 위해 네트워크를 공부하는 것을 강력추천 합니다!
네트워크 데이터 준비의 마지막 단계는 입력을 정규화하고 출력을 원-핫 인코딩하는 것입니다.
Model (모델)
드디어 우리는 모델 아키텍처를 설계할 것입니다. 모델은 네 가지 유형의 레이어를 사용합니다.
LSTM 레이어 는 어떤 시퀀스를 입력으로 넣었을 때 출력으로 또 다른 시퀀스 또는 행렬을 주는 순환신경망입니다.
dropout 레이어 는 모델을 학습시킬 때 오버피팅(overfitting)이 되는 것을 방지하는 방법입니다. 모든 뉴런으로 학습하는 것이 아니라 무작위로 학습을 쓸 뉴런을 정해서 학습을 진행하는 것입니다. mini-batch 마다 랜덤하게 되는 뉴런이 달라지기 때문에 다양한 모델을 쓰는듯한 효과를 냅니다.
Dense 레이어 또는 Fully connected 레이어는 이전 레이어의 모든 뉴런과 결합된 형태의 레이어
Activation 레이어는 신경망이 노드의 출력을 계산하는 데 사용할 활성화 기능을 결정합니다.
model = Sequential()
model.add(LSTM(
256,
input_shape=(network_input.shape[1], network_input.shape[2]),
return_sequences=True
))
model.add(Dropout(0.3))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(256))
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
이제 사용할 여러 레이어에 대한 정보를 네트워크 모델에 추가할 때입니다.
각 LSTM, Dense 및 Activation 레이어에 대해 첫 번째 매개변수는 레이어가 가져야 하는 노드 수입니다. Dropout 레이어의 경우 첫 번째 매개변수는 교육 중에 삭제해야 하는 입력 단위의 비율*입니다. 전체의 노드(위에서 설명한 무작위로 정할 뉴런)를 결정하는 비율입니다.
주의 : tensorflow에 있는 tf.layers.dropout(rate = 0.7)에는 살려야 하는 뉴런의 비율을 의미합니다.
첫 번째 레이어에서는 input_shape 라는 고유한 매개변수가 필요합니다. input_shape 매개변수를 사용하는 목적은 모델을 학습하기 위해서 쓸 데이터의 형태를 네트워크에 알리는 것입니다.
마지막 레이어은 항상 시스템의 서로 다른 출력 수와 동일한 수의 노드를 포함해야 합니다. 이는 네트워크 출력이 우리 클래스와 직접 연결되도록 보장합니다.
이 튜토리얼에서는 LSTM 레이어 3개, Dropout 레이어 3개, Dense 레이어 2개 및 Activation 레이어 1개로 구성된 단순한 네트워크를 사용합니다. 예측의 품질을 향상시킬 수 있는지 확인하기 위해 여러가지 네트워크 구조를 테스트해보는 것을 추천합니다.
각 학습의 반복에 대한 손실을 계산하기 위해, 우리는 범주형 크로스 엔트로피를 사용할 것입니다. 범주형 크로스 엔트로피를 사용하는 이유는 각 출력은 단 한 개의 클래스에만 속해야하고 우리는 두 개 이상의 클래스를 가지고 있기 때문입니다. 또한 네트워크를 최적화하기 위해 RMSprop optimizer를 사용할 것입니다. RMSprop optimizer는 일반적으로 순환신경망에 매우 적합합니다.
filepath = "weights-improvement-{epoch:02d}-{loss:.4f}-bigger.hdf5"
checkpoint = ModelCheckpoint(
filepath, monitor='loss',
verbose=0,
save_best_only=True,
mode='min'
)
callbacks_list = [checkpoint]
model.fit(network_input, network_output, epochs=200, batch_size=64, callbacks=callbacks_list)
일단 네트워크의 아키텍처를 결정했으니 학습을 시작할 시간이 왔습니다. Keras의 model.fit() 함수는 신경망을 학습하는 데 사용됩니다. model.fit() 함수의 첫 번째 파라미터는 앞에서 준비한 입력 시퀀스 목록이고 두 번째 파라미터는 각 출력의 목록입니다. 이 튜토리얼에서는 64개의 샘플을 포함하는 네트워크를 통해 전파되는 각 배치에 대해 200 에폭(반복, epoch) 동안 네트워크를 학습할 것입니다.
우리가 열심히 학습한 것을 잃지 않고도 언제든 훈련을 중단할 수 있도록 우리는 모델 체크포인트를 사용할 것입니다. 모델 체크포인트는 매 에폭마다 네트워크 노드의 가중치를 파일에 저장할 수 있는 방법을 제공합니다. 이것은 우리가 가중치를 잃어 버릴 걱정 없이 손실 값에 만족하면 신경망을 작동시키는 것을 멈출 수 있게 해줍니다. 모델 체크포인트가 없다면 신경망이 모든 200 에폭을 학습할 때까지 기다려야 할 것입니다.
Generating Music (음악 생성하기)
네트워크 학습을 마쳤으니 이제 몇 시간 동안 학습한 네트워크와 함께 즐거운 시간을 보낼 시간입니다.
학습된 신경망을 사용하여 음악을 생성하려면 이전과 같은 상태로 만들어야 합니다. 간단하게 하기 위해 학습 섹션의 코드(chord)를 재사용하여 데이터를 준비하고 전과 동일한 방식으로 네트워크 모델을 설정합니다. 단, 네트워크를 교육하는 대신 학습 섹션에서 저장한 가중치를 모델에 로드합니다.
model = Sequential()
model.add(LSTM(
512,
input_shape=(network_input.shape[1], network_input.shape[2]),
return_sequences=True
))
model.add(Dropout(0.3))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(512))
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
# 각각의 뉴런(노드)의 가중치를 로드합니다.
# 파일에 저장한 학습 결과를 가져오는 것과 같습니다!
model.load_weights('weights.hdf5')
이제 학습된 모델을 사용하여 노트 생성을 시작할 수 있습니다.
우리가 매번 다른 시퀀스를 입력으로 준다면, 아무것도 하지 않고도 매번 다른 결과를 얻을 수 있습니다. 매번 다른 시퀀스를 입력하기 위해서는 랜덤 함수를 이용하면 됩니다!
여기서는 네트워크 출력을 디코딩하는 매핑 기능도 생성해야 합니다. 입력은 categorical 한 것을 숫자로 바꾸었지만 이번엔 반대로 숫자에서 categorical 데이터(정수에서 노트까지)로 매핑합니다.
# 입력 시퀀스를 랜덤하게 주는 부분.
start = numpy.random.randint(0, len(network_input)-1)
# 숫자를 노트로 매핑하는 사전을 생성합니다.
int_to_note = dict((number, note) for number, note in enumerate(pitchnames))
pattern = network_input[start]
prediction_output = []
# 500 개의 노트를 만들어줍니다.
for note_index in range(500):
prediction_input = numpy.reshape(pattern, (1, len(pattern), 1))
prediction_input = prediction_input / float(n_vocab)
# 입력 값에 대해 다음 노트를 예측합니다.
prediction = model.predict(prediction_input, verbose=0)
index = numpy.argmax(prediction)
# 결과값은 숫자가 아닌 노트여야 하므로, 미리 만들어놓은 사전에 숫자를 넣어서 맵핑시킵니다.
result = int_to_note[index]
prediction_output.append(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
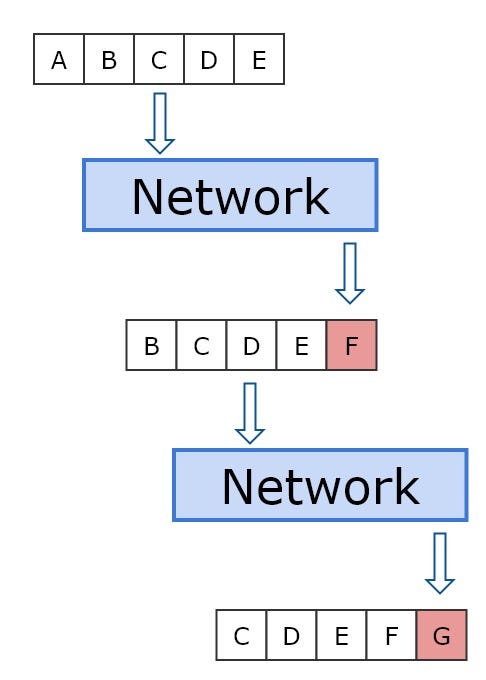
우리는 네트워크를 이용하여 500개의 음을 만들기로 정했습니다. 왜냐하면 500개의 노트는 약 2분 정도의 음악이기 떄문입니다. 그리고 네트워크에게 멜로디를 만들 수 있는 충분한 공간을 주기 때문이기도 합니다. 생성하려는 각 노트에 대해 네트워크에 시퀀스를 제출해야 합니다. 우리가 입력한 첫 번째 시퀀스는 시작 인덱스에 있는 노트 입니다. 우리는 다음 출력 시퀀스를 얻기 위해서, 출력된 시퀀스에서 입력으로 사용된 부분을 제거하고 그것을 입력 시퀀스로 씁니다. figure2 를 보면 더 이해가 쉬울 것입니다.
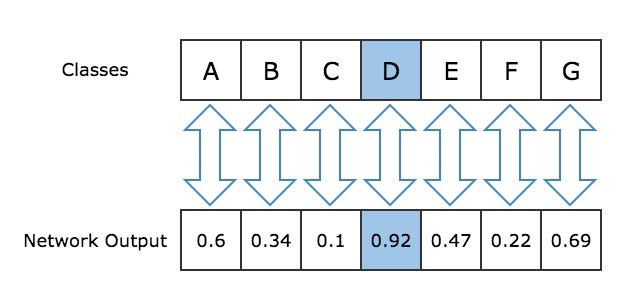
네트워크 출력에서 가장 가능성이 높은 예측값을 결정하기 위해 가장 높은 확률의 인덱스를 추출합니다. 출력 배열에서 인덱스 X의 값은 X가 다음 노트가 될 확률에 해당합니다. 그림 3이 이해를 도와줄 것입니다.
그런 다음 리스트에 모든 출력을 수집합니다.이제 리스트에 인코딩된 모든 노트와 코드(chord) 표시가 있으므로 노트의 디코딩을 시작하고 노트와 코드(chord) 개체의 리스트 만들 수 있습니다.
이 과정에서는 다시 music21을 사용할 것입니다.
먼저 디코딩 중인 출력이 노트인지 또는 코드(chord)인지 확인해야 합니다.
패턴이 코드(chord) 인 경우 문자열을 여러 노트로 분할해야 합니다. 그런 다음 각 노트의 문자열 표현을 반복하여 각 노트에 대한 노트 개체를 만듭니다. 그러면 각 노트를 포함하는 코드(chord) 개체를 만들 수 있습니다.
패턴이 노트 인 경우 패턴에 포함된 계이름을 표현하는 문자열 표현을 사용하여 노트 개체를 만듭니다.
각 반복이 끝날 때마다 오프셋이 0.5씩 증가하고(0.5 는 우리가 이전 섹션에서 결정했습니다) 생성된 노트/코드(chord) 개체가 리스트에 추가됩니다.
offset = 0
output_notes = []
# 모델에 의해 예측된 값을 바탕으로 노트와 코드(chord) 객체를 만듭니다.
for pattern in prediction_output:
# 패턴(출력값)이 코드(chord) 일 때
if ('.' in pattern) or pattern.isdigit():
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
new_note = note.Note(int(current_note))
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
new_chord = chord.Chord(notes)
new_chord.offset = offset
output_notes.append(new_chord)
# 패턴이(출력값이) 노트일 때
else:
new_note = note.Note(pattern)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
# 각 반복마 오프셋을 0.5 씩 증가시켜 줍니다.
# 그렇지 않으면 같은 오프셋에 음이 쌓이게 됩니다.
offset += 0.5
이제 네트워크에서 생성된 노트 및 코드(chord) 리스트를 매개 변수로 사용하여 Music21 Stream 객체를 만들 것입니다. 진짜 음악을 만드는 부분입니다. 마지막으로 네트워크에서 생성된 음악을 저장할 MIDI 파일을 만들기 위해 Music21 툴킷의 쓰기 기능을 사용하여 스트림을 파일에 씁니다.
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp='test_output.mid')
Results (결과)
이제 그 결과에 놀랄 타이밍입니다! Figure 4는 LSTM 네트워크를 사용하여 생성된 음악의 시트입니다. 우리는 음악 시트를 보고 한 눈에 스트럭처가 있다는 것을 알 수 있습니다. 특히 두 번째 페이지의 세 번째 줄에서 마지막 줄에서 두드러지게 보입니다.
음악에 대해 잘 알고 있고 음악 표기법을 읽을 수 있는 사람들은 종이에 이상한 음들이 흩어져 있는 것을 알 수 있을 것입니다. 이것은 신경망이 완벽한 멜로디를 만들 수 없기 때문에 생기는 결과입니다. 현재 구현에서는 몇 가지 잘못된 사항이 있으며 더 나은 결과를 얻으려면 더 큰 네트워크가 필요합니다.

Figure 4: LSTM 네트워크로 만들어진 음악의 예
이 비교적 얕은 네트워크에서의 결과는 임베드 1의 예 음악에서 들을 수 있듯이 여전히 매우 인상적입니다. 여기 임베드 1을 들어볼 수 있습니다.
Future Work
우리는 간단한 LSTM 네트워크와 352 개의 클래스를 사용하여 놀라운 결과와 아름다운 멜로디를 만드는 것을 성공했습니다. 하지만 개선할 수 있는 몇 가지가 있습니다.
첫째, 현재 구현에서는 노트의 지속시간과 노트 간의 오프셋을 다양하게 지원하지 않습니다. 이를 위해 각 기간마다 더 많은 클래스를 추가하고 노트 사이에 나머지 기간을 나타내는 휴식 클래스를 추가할 수 있습니다.
더 많은 클래스를 추가하여 만족스러운 결과를 얻으려면 LSTM 네트워크의 깊이가 더 깊어져야 하는데, 이 네트워크에는 훨씬 더 성능좋은 컴퓨터가 필요합니다. 이 네트워크를 학습시키는데 집에서 사용하는 노트북으로 20시간 정도 걸렸기 때문입니다.
두 번째, 피스들에 시작과 끝을 더하세요. 네트워크가 현재로선 조각들 간의 구분이 없기 때문에, 네트워크는 한 조각이 어디서 끝나는지 모르고 다른 하나가 시작되는지 모릅니다. 이렇게 하면 네트워크가 지금처럼 갑자기 생성된 부분을 끝내지 않고 처음부터 끝까지 다시 한 피스를 생성할 수 있습니다.
셋째, 알 수 없는 노트를 처리하는 방법을 추가합니다. 현재는 네트워크가 모르는 메모를 접할 경우 에러 상태가 .버립니다. 이 문제를 해결하기 위한 가능한 방법은 알 수 없는 노트와 가장 유사한 노트 또는 코드(chord)를 찾는 것입니다.
마지막으로, 데이터 세트에 악기를 추가합니다. 현재로서, 네트워크는 하나의 악기만 있는 부품만 지원합니다. 오케스트라 전체를 지원하기 위해 여러개의 악기를 예측할 수 있도록 확장해보는 것 역시 흥미로울 것입니다.
Conclusion (결과)
이 튜토리얼에서는 LSTM 신경 네트워크를 생성하여 음악을 생성하는 방법을 보여 줍니다. 결과는 완벽하지 않을 수도 있지만 그럼에도 불구하고 그것들은 꽤 인상적이고 신경망이 음악을 만들어 낼 수 있고 더 복잡한 음악 작품을 만드는 데 사용될 수 있다는 것을 보여줍니다.
참고 사이트
이 글은 2018 컨트리뷰톤에서
Contribute to Keras프로젝트로 진행했습니다.
Translator: 박정현, 송문혁
Translator email : parkjh688@gmail.com, firefinger07@gmail.com