GAN with Keras: Application to Image Deblurring
이 글은 케라스 라이브러리를 이용해 이미지의 흐린부분을 없애주는 효과에 GAN을 적용해보는 튜토리얼입니다.
주요 키워드
- GAN(Generative Adversarial Networks, 생성적 적대 신경망)
- Image Deblur
- Keras
- Deep Learning
- Tutorial

2014년, 이안 굿펠로우(Ian Goodfellow)가 GAN을 소개했습니다. 이 글에선 케라스로 설계한 GAN으로 이미지 흐림 제거를 실행하는데 초점을 두고 있습니다.
본 글에 대한 원본 논문과 그에 대한 파이토치 코드를 보기 바랍니다. 본 글의 모든 케라스 코드들은 이곳에서 이용할 수 있습니다.
GAN 빠르게 복습하기
GAN에서, 두 개의 신경망 각각 견제하면서 학습을 합니다. 생성자(generator)는 진짜같은 가짜 입력값을 생성해서 식별자(discriminator)를 속입니다. 식별자는 입력값이 진짜인지 가짜인지 말해줍니다.
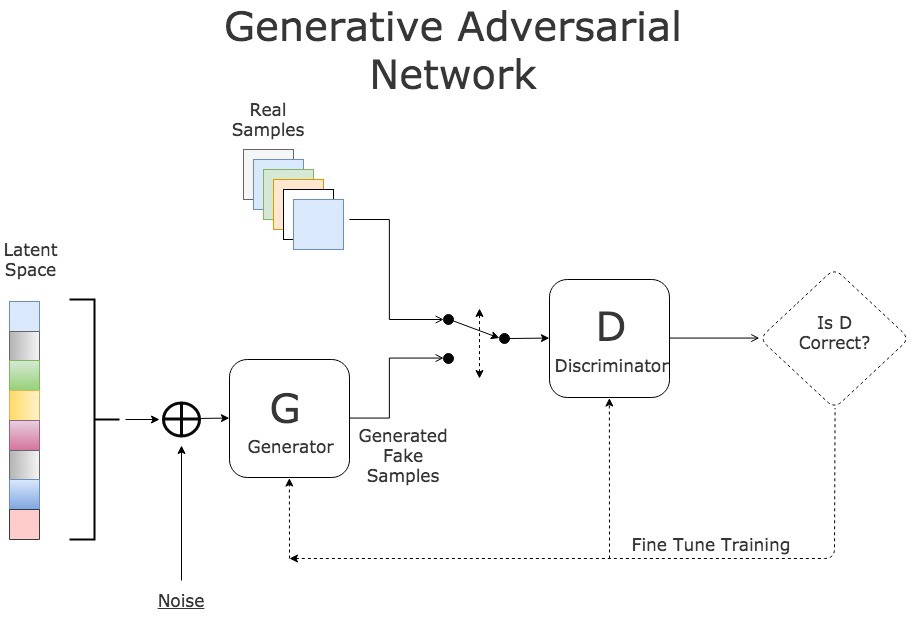
GAN Training Process - source
학습은 아래 3가지 스텝으로 이루어집니다.
- 생성자를 노이즈(noise)기반의 가짜 입력값 생성하는데 사용하세요.
- 식별자를 진짜 입력값과 가짜 입력값 둘 다 학습시키세요.
- 전체 모델을 학습 시키세요 : 모델은 생산자와 연결된 식별자로 설계되어 있습니다.
3번째 단계에서 식별자의 가중치(weights)는 프리즈(freeze)됩니다.
두 신경망이 연결된 이유는 생산자의 결과값에 대한 피드백이 불가능 하기 때문입니다. 고로, 유일한 측정 방법은 생성된 결과들을 식별자가 얼마나 받아들이는 데에 있습니다.
이는 GAN 구조를 간단하게 보여줍니다. 만약 쉽게 느껴지지 않는다면, 이 글을 참조하세요.
데이터
이안 굿펠러는 처음에 MNIST 데이터를 생성하는데 GAN 모델을 적용했습니다. 이 글에선, 이미지의 흐린부분을 제거하기 위해 GAN을 사용합니다.
데이터 세트는 GOPRO를 사용할 겁니다. 가벼운 버전(9GB) 혹은 전체 버전(35GB)를 다운받을 수 있습니다. 여기엔 인위적으로 흐릿한 다양한 거리의 풍경 이미지가 있습니다. 데이터 세트는 씬(scene)별로 하위 폴더로 나뉘어져 있습니다.
처음에 두 폴더 A(흐릿한), B(선명한)로 이미지들을 분배합니다. A와 B의 구조는 원래 pix2pix에 해당됩니다. 해당 작업을 위해 이곳에 스크립트를 만들어 놨습니다. 사용 방법은 README에 나와있습니다!
모델
학습 과정은 동일합니다. 먼저, 신경망 구조를 확인해 봅시다!
생성자
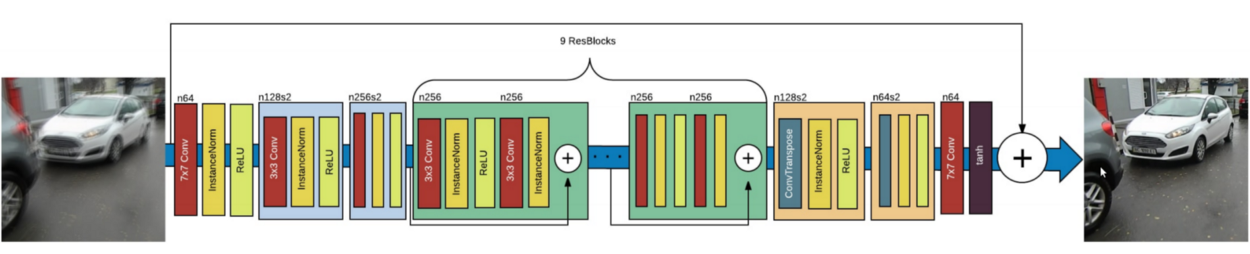
DeblurGAN 생성자 신경망의 구조입니다 - Source
핵심은 원본 이미지의 업샘플링(upsampling)에 적용되는 9개의 ResNet 블럭(block)들 입니다.
from keras.layers import Input, Conv2D, Activation, BatchNormalization
from keras.layers.merge import Add
from keras.layers.core import Dropout
def res_block(input, filters, kernel_size=(3,3), strides=(1,1), use_dropout=False):
"""
순차 API(sequential API)를 사용해 케라스 Resnet 블럭을 인스턴스화 합니다.
:매개변수
- input: 입력 텐서(tensor)
- filters: 사용하려는 필터 수
- kernel_size: 컨볼루션(convolution)을 위한 커널(kernel) 형태
- strides: 컨볼루션을 위한 스트라이드(strides) 형태
- use_dropout: 드롭아웃(dropout) 사용 여부를 결정하는 boolean 값
:반환
- 케라스 모델
"""
x = ReflectionPadding2D((1,1))(input)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
if use_dropout:
x = Dropout(0.5)(x)
x = ReflectionPadding2D((1,1))(x)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,)(x)
x = BatchNormalization()(x)
# 입력과 출력 사이에 직접 연결하는 두 개의 컨볼루션 레이어(layer)
merged = Add()([input, x])
return merged
위 코드는 res_block.py에서 볼 수 있습니다.
ResNet 레이어는 기본적으로 최종 출력을 만드는 입력과 출력이 포함된 콘볼루션 레이어입니다.
from keras.layers import Input, Activation, Add
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.layers.core import Lambda
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from layer_utils import ReflectionPadding2D, res_block
ngf = 64
input_nc = 3
output_nc = 3
input_shape_generator = (256, 256, input_nc)
n_blocks_gen = 9
def generator_model():
"""생성자 구조를 생성합니다."""
# 현재 버전 : ResNet 블럭
inputs = Input(shape=image_shape)
x = ReflectionPadding2D((3, 3))(inputs)
x = Conv2D(filters=ngf, kernel_size=(7,7), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 필터 수를 증가시킵니다.
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
x = Conv2D(filters=ngf*mult*2, kernel_size=(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 9개의 ResNet 블럭을 적용시킵니다.
mult = 2**n_downsampling
for i in range(n_blocks_gen):
x = res_block(x, ngf*mult, use_dropout=True)
# 필터 수를 3(RGB)로 줄입니다.
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
x = Conv2DTranspose(filters=int(ngf * mult / 2), kernel_size=(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = ReflectionPadding2D((3,3))(x)
x = Conv2D(filters=output_nc, kernel_size=(7,7), padding='valid')(x)
x = Activation('tanh')(x)
# 입력에서 출력으로 직접 연결되도록 하고 [-1, 1]로 중심을 바꿉니다.
outputs = Add()([x, inputs])
outputs = Lambda(lambda z: z/2)(outputs)
model = Model(inputs=inputs, outputs=outputs, name='Generator')
return model
위 코드는 generator.py에서 볼 수 있습니다.
계획대로, 9개의 ResNet 블럭들은 입력 이미지의 업샘플링된 버전에 적용됩니다. 입력 부위에서 출력까지 레이어들을 연결시키고 정규화된 출력이 되도록 2로 나눕니다.
이제까지 생성자에 대해 다뤘습니다. 이제 식별자의 구조를 확인해 보겠습니다.
식별자
식별자의 목표는 입력 이미지가 인위적으로 생성되었는지 확인하는 것입니다. 그러므로, 식별자의 구조는 컨볼루션이고 단일값으로 출력됩니다.
from keras.layers import Input
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D
from keras.layers.core import Dense, Flatten
from keras.layers.normalization import BatchNormalization
from keras.models import Model
ndf = 64
output_nc = 3
input_shape_discriminator = (256, 256, output_nc)
def discriminator_model():
"""식별자 구조를 생성합니다."""
n_layers, use_sigmoid = 3, False
inputs = Input(shape=input_shape_discriminator)
x = Conv2D(filters=ndf, kernel_size=(4,4), strides=2, padding='same')(inputs)
x = LeakyReLU(0.2)(x)
nf_mult, nf_mult_prev = 1, 1
for n in range(n_layers):
nf_mult_prev, nf_mult = nf_mult, min(2**n, 8)
x = Conv2D(filters=ndf*nf_mult, kernel_size=(4,4), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.2)(x)
nf_mult_prev, nf_mult = nf_mult, min(2**n_layers, 8)
x = Conv2D(filters=ndf*nf_mult, kernel_size=(4,4), strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.2)(x)
x = Conv2D(filters=1, kernel_size=(4,4), strides=1, padding='same')(x)
if use_sigmoid:
x = Activation('sigmoid')(x)
x = Flatten()(x)
x = Dense(1024, activation='tanh')(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=x, name='Discriminator')
return model
위 코드는 discriminator.py에서 볼 수 있습니다.
마지막 단계는 전체 모델을 생생합니다. 이번 GAN의 특징은 입력값이 실제 이미지이고 노이즈가 아닌 점입니다. 그러므로, 우리는 생성자의 출력값에 대한 직접적인 피드백을 갖습니다.
from keras.layers import Input
from keras.models import Model
def generator_containing_discriminator_multiple_outputs(generator, discriminator):
inputs = Input(shape=image_shape)
generated_images = generator(inputs)
outputs = discriminator(generated_images)
model = Model(inputs=inputs, outputs=[generated_images, outputs])
return model
위 코드는 gan.py에서 볼 수 있습니다.
어떻게 두 손실값을 이용해 이 특징들을 최대한 활용하는지 봅시다.
학습
손실값들
생성자의 마지막과 전체 모델의 마지막, 두 단계에서 손실값들을 추출합니다.
첫번째 손실값은 생성자의 출력값에 대해 직접적으로 계산된 판단 손실값(perceptual loss)입니다. 이 손실값은 GAN 모델이 흐릿한 작업에 초점을 맞춰져 있습니다. 이는 VGG16의 첫번째 컨볼루션의 결과와 비교합니다.
import keras.backend as K
from keras.applications.vgg16 import VGG16
from keras.models import Model
image_shape = (256, 256, 3)
def perceptual_loss(y_true, y_pred):
vgg = VGG16(include_top=False, weights='imagenet', input_shape=image_shape)
loss_model = Model(inputs=vgg.input, outputs=vgg.get_layer('block3_conv3').output)
loss_model.trainable = False
return K.mean(K.square(loss_model(y_true) - loss_model(y_pred)))
위 코드는 perceptual_loss.py에서 볼 수 있습니다.
두번째 손실값은 전체 모델의 출력값에 대해 수행되는 와서슈타인 손실값(wasserstein loss)입니다. 이는 두 이미지간의 차이의 평균을 가져옵니다. GAN의 컨버전스(convergence)를 개선시킨 것으로도 알려져 있습니다.
import keras.backend as K
def wasserstein_loss(y_true, y_pred):
return K.mean(y_true*y_pred)
위 코드는 wasserstein_loss.py에서 볼 수 있습니다.
학습 과정
첫 번째로 데이터를 불러오고 모든 모델을 초기화합니다. 데이터를 불러오기 위해 따로 만든 함수를 사용하고 아담 최적화 함수(Adam optimazer)를 추가합니다. 식별자가 학습이 되는걸 방지하기 위해 케라스내 학습 옵션을 설정합니다.
# 데이터를 불러옵니다.
data = load_images('./images/train', n_images)
y_train, x_train = data['B'], data['A']
# 모델을 초기화합니다.
g = generator_model()
d = discriminator_model()
d_on_g = generator_containing_discriminator_multiple_outputs(g, d)
# 아담 최적화 함수를 초기화 해줍니다.
g_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
d_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
d_on_g_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# 모델을 컴파일(compile)해줍니다.
d.trainable = True
d.compile(optimizer=d_opt, loss=wasserstein_loss)
d.trainable = False
loss = [perceptual_loss, wasserstein_loss]
loss_weights = [100, 1]
d_on_g.compile(optimizer=d_on_g_opt, loss=loss, loss_weights=loss_weights)
d.trainable = True
위 코드는 gan_training_initialization.py에서 볼 수 있습니다.
그리고, 설정한 에폭(epoch)만큼 실행하면서 데이터 세트를 나눠서 배치(batch)에 분배합니다.
for epoch in range(epoch_num):
print('epoch: {}/{}'.format(epoch, epoch_num))
print('batches: {}'.format(x_train.shape[0] / batch_size))
# 이미지를 임의로 섞어서 배치에 분배합니다.
permutated_indexes = np.random.permutation(x_train.shape[0])
for index in range(int(x_train.shape[0] / batch_size)):
batch_indexes = permutated_indexes[index*batch_size:(index+1)*batch_size]
image_blur_batch = x_train[batch_indexes]
image_full_batch = y_train[batch_indexes]
위 코드는 gan_training_batches.py에서 볼 수 있습니다.
마지막으로, 두 개의 손실 함수를 기반으로 식별자와 생성자를 성공적으로 학습시킵니다. 생성자를 통해 가짜 입력값을 생성합니다. 식별자가 진짜와 가짜를 식별하도록 훈련시키고, 전체 모델을 학습시킵니다.
for epoch in range(epoch_num):
for index in range(batches):
# [배치 준비]
# 가짜 입력값을 생성합니다.
generated_images = g.predict(x=image_blur_batch, batch_size=batch_size)
# 실제, 가짜 입력값을 기반으로 식별자를 학습시킵니다.
for _ in range(critic_updates):
d_loss_real = d.train_on_batch(image_full_batch, output_true_batch)
d_loss_fake = d.train_on_batch(generated_images, output_false_batch)
d_loss = 0.5 * np.add(d_loss_fake, d_loss_real)
d.trainable = False
# 식별자의 판단과 생성된 이미지를 기반으로 생성자를 학습시킵니다.
d_on_g_loss = d_on_g.train_on_batch(image_blur_batch, [image_full_batch, output_true_batch])
d.trainable = True
위 코드는 gan_training_fit.py를 통해 보실 수 있습니다.
반복 구간의 확실한 이해를 위해 Github를 참조하세요.
작업 환경
본 글을 위해 Deep Learning AMI(3.0)과 같이 AWS 인스턴스(p2.xlarge)를 사용했습니다. 학습 시간은 GOPRO의 가벼운 버전을 사용해 대략 5시간(에폭 50회)이 걸렸습니다.
이미지 흐림 제거 결과

왼쪽부터 오른쪽으로 : 원본, 흐린 이미지, GAN 출력값
위 결과는 본 글의 케라스 Deblur GAN의 결과입니다. 짙은 흐림이 있음에도 신경망이 흐린 부분을 줄이고 이미지를 좀 더 선명하게 형성했습니다. 자동차 불빛과 나뭇가지들이 선명해졌습니다.

왼쪽 : GOPRO 테스트 이미지, 오른쪽 : GAN 출력값
한계점은 손실함수로 VGG를 사용하면 나타나는 패턴으로 위 이미지 상단에 나타나는 패턴입니다.

왼쪽 : GOPRO 테스트 이미지, 오른쪽 : GAN 출력값
만약 컴퓨터 비전에 흥미가 있다면, [케라스를 사용한 컨텐츠 기반의 이미지 검색]을 한번 보십시오. 아래는 GAN관련 참조 목록입니다.

왼쪽 : GOPRO 테스트 이미지, 오른쪽 : GAN 출력값
GAN 참고 자료
- NIPS 2016 : 생성적 적대적 신경망 by 이안 굿펠로우
- ICCV 2017 : GAN 튜토리얼
- 케라스를 이용해 GAN 구현 by 에릭 린더-노렌
- GAN 목록 by deeplearning4j
- 진짜 놀라운 GAN by 호거 캐서
저자 : 당신이 이 글(케라스로 설계한 GAN으로 이미지 흐림 제거)을 즐겼으면 합니다! 밑에 팔로우 버튼 잊지마세요!
이 글은 2018 컨트리뷰톤에서
Contributue to Keras프로젝트로 진행했습니다.
Translator : mike2ox (Moonhyeok Song)
Translator Email : firefinger07@gmail.com